AI development loops

Whether you are hot-gluing pasta art or developing world-class software, the archetypal development loop is:
- Try something
- See what happens
- Repeat
To the extent that this loop is fast and provides clear signal, it frees you to try things and incrementally improve them.
With AI development, speed and signal are complicated by a number of factors:
- Response times are slow
- Inputs are often unstructured and generated by humans. As a result, there are an unbounded number of possible inputs with minute variations. So it’s hard to select a realistic scenario (or set of scenarios) to “see what happens”
- Outputs are unstructured and non-deterministic, making it difficult to assess the result
To enable a useful development loop in these circumstances, it is necessary to add a couple of supporting activities that address these complications. These form the three core loops of AI development:
- Exploration – A quicker feedback loop for trying things. (This provides speed.)
- Evaluation – A testing approach that automatically applies a set of test inputs and assesses the results with a set of scorers. (This provides signal.)
- Data Collection – A process for finding interesting data from production to use as test inputs. (This ensures the signal is reliable.)
Braintrust provides tools that support all three of these loops as well as the handoffs between them. This tightens the feedback loop and makes the testing and results easier to work with.
Loop 1: Exploration
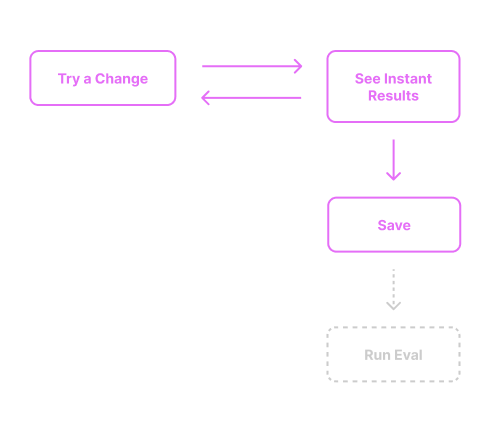
The goal of this loop is to play around—to quickly try out changes in a low-stakes environment and get a sense of whether a direction seems good before investing in it further.
Strategically, you try a change, do a simple test, and manually assess the result. If things look promising, you apply the change to a branch of your codebase and run an evaluation.
Steps
- Develop/make a change (For example, tweak the prompt)
- Manually test on one or more inputs and see instant results
- Do something with them. (For example, save and trigger a new evaluation)
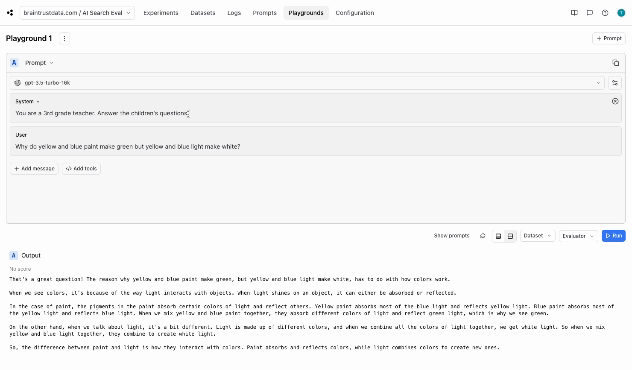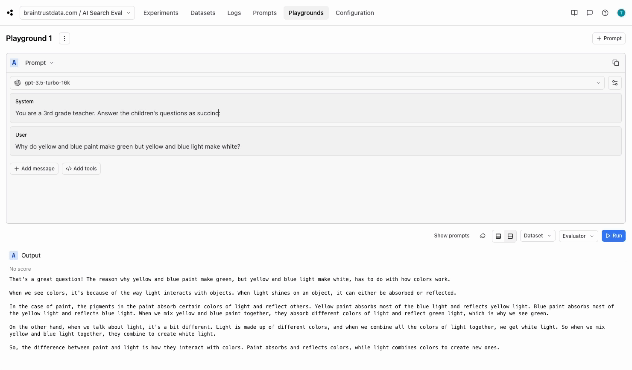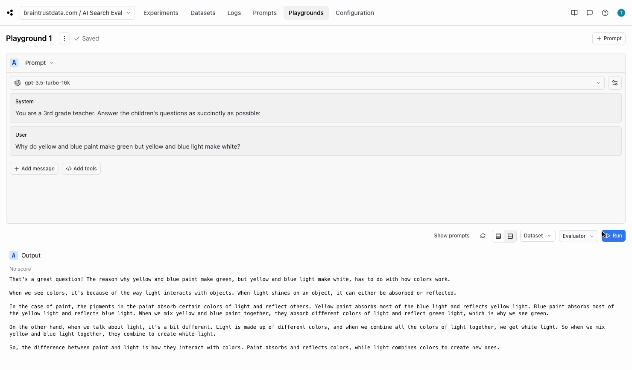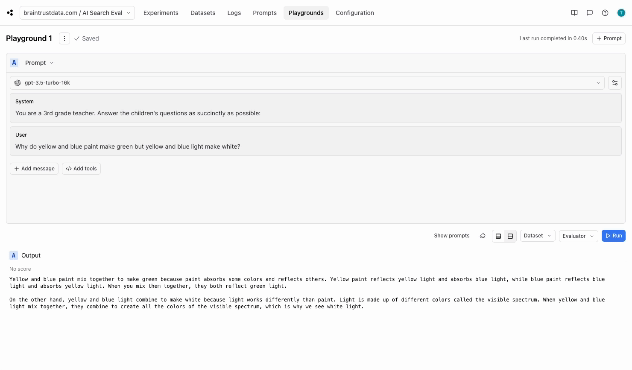
Braintrust supports this through our Playgrounds, which are built for rapid iteration. You can test prompts, tweak them, try out different models, and even access test inputs from your datasets.
Loop 2: Evaluation
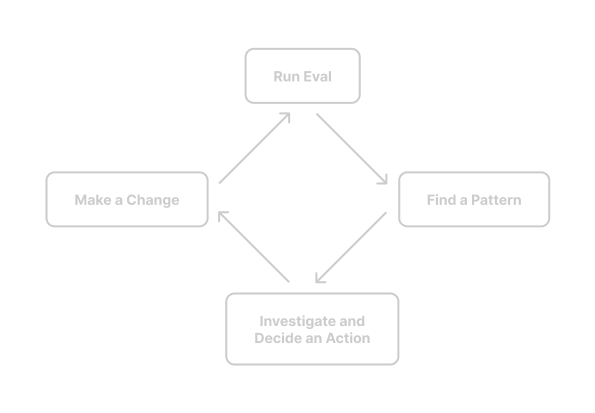
The goal of this loop is to get high certainty about the impact of a change. It allows you to ensure that a change really results in the desired improvement and that nothing will break when you merge it.
Strategically, you make a change, test it on a suite of test cases and scorers, and assess the results to determine next steps.
Steps
- Make a change in:
- Prompts, model params, and app code,
- Fine tuning,
- Scorers, or
- Test cases
- Evaluate. (Run each test case and apply the scorers to the results.)
- View the results to:
- Determine whether the change had the intended effect
- Find a pattern to investigate
- Analyze outputs and traces in detail, and decide the next action
- Repeat
This is the main experience in Braintrust. It supports robust, methodical testing with high convenience. Braintrust makes it accessible for any software engineer to define and run evals on golden datasets and to do it every time you make a change or send a PR. We also allow you to view the results in detail, including an entire trace, with comparisons to past results.
Loop 3: Data collection
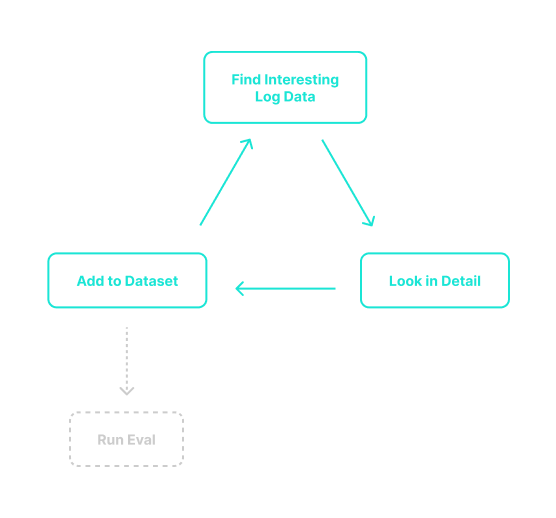
The goal of this loop is to build high-quality datasets for testing. Strategically, identify patterns and interesting results in your production logs, capture the inputs, and write good expected outputs. You then use these input+expected tuples to generate signal in the other two loops.
Steps
- Search for patterns or problems in production logs
- Analyze the inputs, outputs, and traces in detail and select inputs to add as test cases
- Repeat
Braintrust helps you do this in a bunch of ways. The first is our logs. They provide robust filtering and visualizations to help you find noteworthy production user interactions. When you’ve found an interesting interaction, our logs give you access to full details of it, including input, output, trace details with all spans in context, and scores. The second is our datasets. They hold your test cases, allowing you to store interesting real-world examples and to access them to use in evals and exploration.
Conclusion
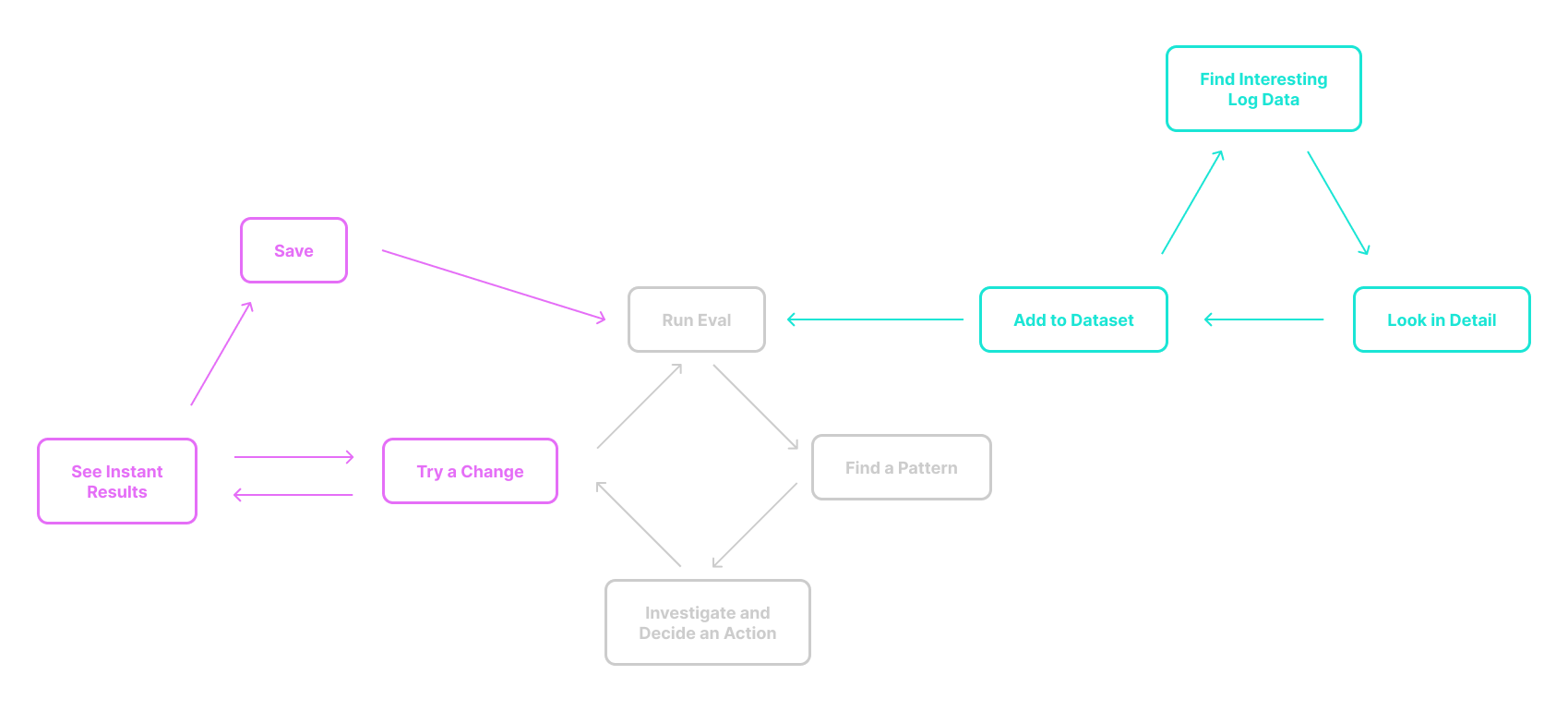
The ability to enact AI development is gated by the ability to flow through each of these loops and to connect them to each other. This can be hard to do well, but Braintrust can help. One thing Braintrust can particularly help with is the flow between the three loops. Because evals, logs, and datasets have the same data structure, Braintrust makes it really straightforward to move data from a log row to a dataset row to an eval row, ensuring your loops can flow into each other.